
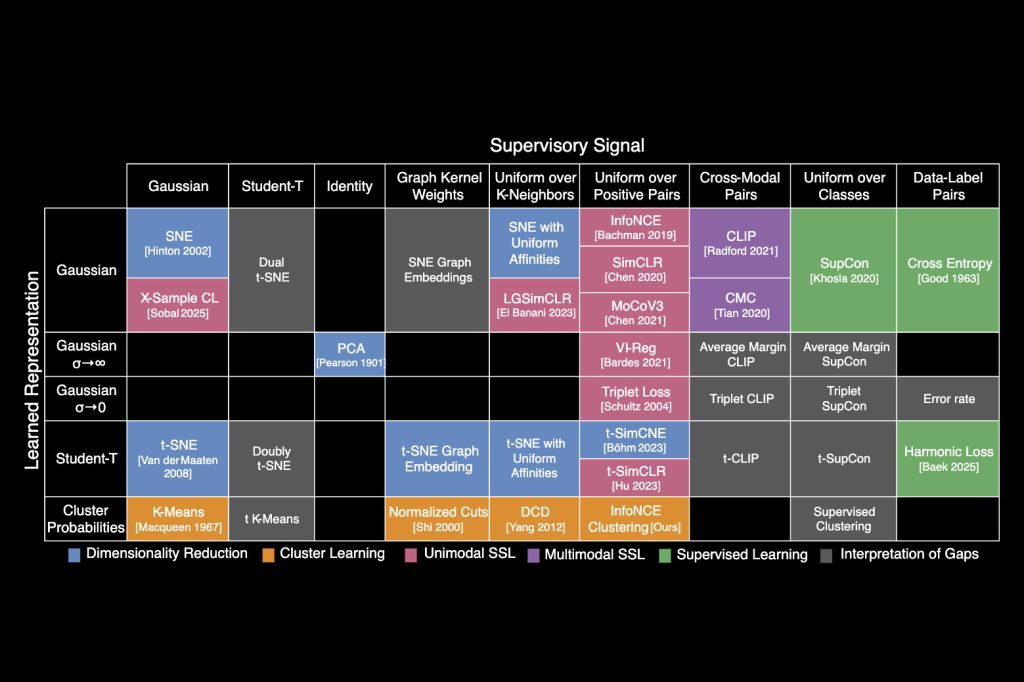
پژوهشگران مؤسسه MIT چارچوبی نوین معرفی کردهاند که مانند یک جدول تناوبی برای الگوریتمهای یادگیری ماشین عمل میکند. این جدول، نحوهی ارتباط بیش از ۲۰ الگوریتم کلاسیک یادگیری ماشین را به نمایش میگذارد و میتواند مسیر را برای توسعه الگوریتمهای هوش مصنوعی (AI) جدید هموار سازد.
برای مثال، تیم پژوهشی با ترکیبکنندهای از دو الگوریتم مختلف، موفق به ساخت الگوریتمی برای طبقهبندی تصاویر شدند که عملکردی تا ۸ درصد بهتر از بهترین روشهای موجود ارائه میدهد.
ایده اصلی این جدول از این اصل ساده آغاز شد که تمامی این الگوریتمها یک نوع خاص از رابطه میان دادهها را یاد میگیرند. با وجود تفاوت در روشها، پایه ریاضی آنها مشابه است. محققان با بررسی دقیق این روشها، قادر شدند معادلهای واحد را استخراج کنند که اساس بسیاری از الگوریتمهای کلاسیک هوش مصنوعی را تشکیل میدهد.
با تکیه بر این معادله، پژوهشگران روشهای محبوب را بازتعریف کرده و آنها را در قالب یک جدول مرتب کردند؛ مشابه آنچه دانشمندان با جدول تناوبی عناصر شیمیایی انجام دادند. این جدول تناوبی یادگیری ماشین نهتنها الگوریتمهای شناختهشده را نشان میدهد، بلکه “جایهای خالی” دارد که وجود الگوریتمهای جدید را پیشبینی میکند که هنوز کشف نشدهاند.
انقلاب در طراحی الگوریتمها
به گفته شادن الشمری، دانشجوی دکترا در MIT و نویسنده اصلی این تحقیق، این جدول ابزاری به محققان ارائه میدهد تا بتوانند بدون بازتکرار ایدههای قبلی، الگوریتمهایی نو خلق کنند. او میگوید: «ما یادگیری ماشین را دیگر فقط به شکل یک رمز و راز نمیبینیم، بلکه آن را به عنوان یک سیستم ساختاریافته بررسی میکنیم که قابل کشف و گسترش است.»
الشمری به همراه تیمی شامل پژوهشگرانی از Google AI، مایکروسافت و آزمایشگاه CSAIL در MIT موفق به توسعه چارچوبی به نام Information Contrastive Learning یا I-Con شدهاند. این چارچوب الگوریتمهای مختلف را بر اساس نوع ارتباطی که میان دادهها میآموزند دستهبندی میکند.
یکی از جالبترین کشفیات آنها زمانی رخ داد که الشمری متوجه شباهت میان الگوریتم کلاسترینگ (دستهبندی تصاویر مشابه) و یادگیری تضادگرایانه شد. بررسیهای بیشتر نشان داد که میتوان هر دوی این الگوریتمها را با استفاده از یک معادله مشترک توضیح داد. مارک همیلتون، نویسنده ارشد میگوید: «تقریباً این معادله وحدتبخش را اتفاقی کشف کردیم، و بعد هر روش دیگری را امتحان کردیم و دیدیم که آنها هم قابل گنجاندن در این چارچوب هستند.»
کشفهای آینده در دل جدول تناوبی الگوریتمها
پژوهشگران با پر کردن یکی از خلأهای جدول خود از طریق ترکیب ایدههای الگوریتم یادگیری تضادگرایانه با دستهبندی تصویر، موفق شدند الگوریتم جدیدی توسعه دهند که دقت طبقهبندی تصاویر بدون برچسب را ۸ درصد نسبت به بهترین روش موجود افزایش داد. آنها همچنین نشان دادند که روشی برای حذف سوگیری دادهها که ابتدا برای یادگیری تضادگرایانه توسعه یافته بود، میتواند در الگوریتمهای دستهبندی نیز عملکرد آنها را بهبود دهد.
انعطافپذیری جدول تناوبی استادگی بالایی دارد؛ محققان میتوانند سطرها و ستونهای جدیدی برای نمایش انواع دیگر ارتباط میان دادهها اضافه کنند. به گفته همیلتون، این چارچوب ابزاری قدرتمند برای شکستن کلیشهها به محققان ارائه میدهد: «تنها با یک معادله زیبا که ریشه در نظریه اطلاعات دارد میتوان الگوریتمهایی غنی را از یک قرن پژوهش در یادگیری ماشین استخراج کرد. این یک دریچه تازه برای پیشرفتهای آتی است.»
یایر ویس، استاد دانشگاه عبری اورشلیم که در این پروژه نقش نداشته، میافزاید: «در دنیایی پر از مقالات فراوان، تحقیقاتی که بتوانند الگوریتمها را یکپارچه کنند بسیار باارزش و نادر هستند. I-Con نمونهای درخشان از این رویکرد یکپارچهگر است و امیدوارم دیگر محققان نیز از آن الهام بگیرند.»
این پژوهش با حمایت نیروی هوایی ایالات متحده، بنیاد ملی علوم آمریکا و شرکت Quanta Computer انجام شده است.